Core Lecture 4a Policy Gradients and Actor Critic -- Pieter Abbeel
Reinforcement Learning is interesting!

终于到Policy Gradient方法了!
一、引言
reinforcement learning研究的是智能体agent与环境environment进行交互,在交互的过程中学习的问题,RL的根本目的是进行策略的优化,希望最终能够获得最优秀的策略。策略(policy)指的就是一个函数,输入一个当前状态state,输出一个动作action(的分布),相当于给agent指明了一条路线,告诉agent在这个状态下应该如何行动,是一个路线图一样的存在。自reinforcement learning建立以来,人们尝试了多种方法希望求得这个最优policy,对这些方法及方法之间的关系进行大致的分类,结果如下图所示。
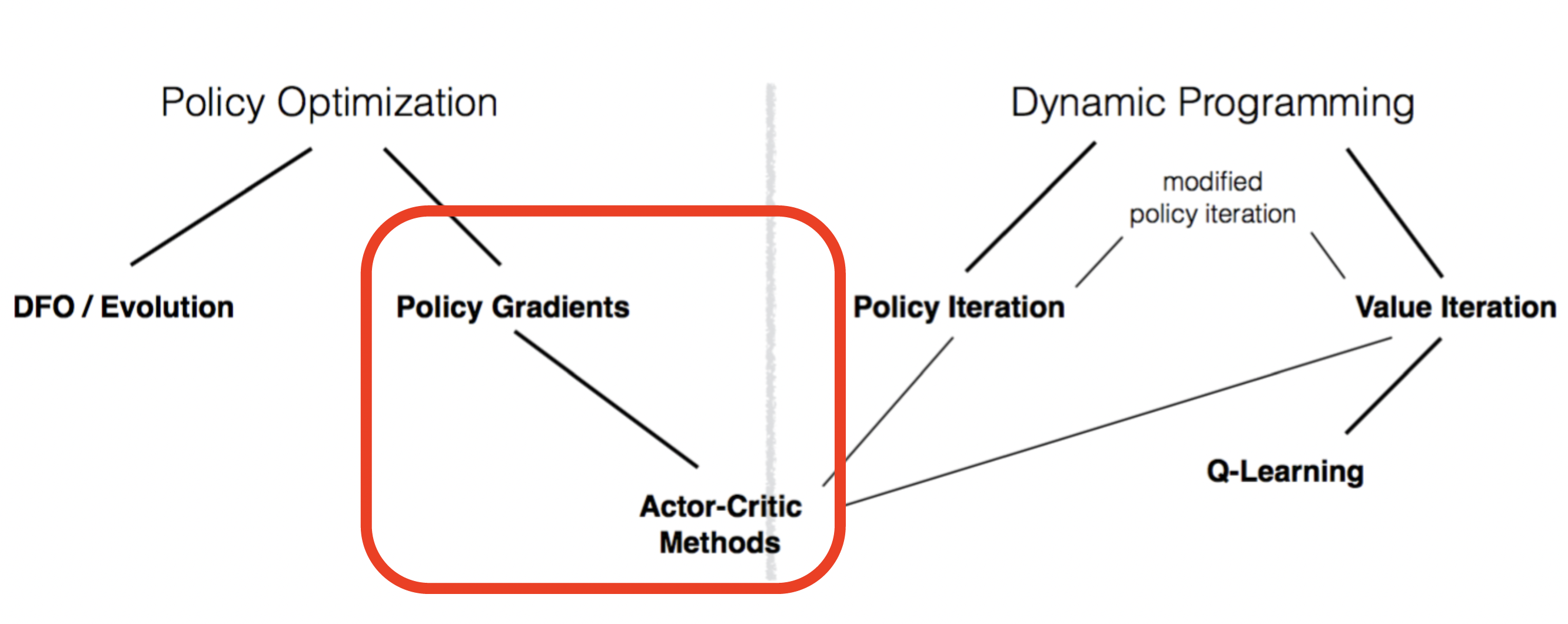
可以看到我们之前讨论过的方法基本都属于Dynamic Programming(动态规划)范畴,通过不断的迭代从简单想复杂推进,直至满足Q、V自洽方程组,Lecture 1中提到了Value Iteration方法(主要是state value)以及policy iteration方法,前者是通过对整个空间进行充分的探索,当对整个空间充分了解以后,策略就退化成了简单的greedy方法;后者则是一个不太一样的思路,着眼于policy的本质(给定状态进行动作选择),先对policy进行评估,获得遵循该policy全空间的value function,之后再根据评估的结果按照贪心的原则对policy进行修正,直到收敛为止。以上讨论的这两个方法的操作都是较为初级的,在之后我们详细讨论了value iteration中的Q-Learning方法,相比于state iteration方法,Q-Learning的策略更加明显,不需要采用argmax,可以直接取max值选择。在模型未知(model free)的情况下Q-Learning可以采用sample的方法,结合TD方法进行学习,每次设定一个target,以一定的学习率像其逼近。Q-Learning又有一系列变式,从记录所有状态-动作组合的Tabular Q-Learning到参数化的approximate Q-learning,再到终极形态DQN,以及对DQN存在的一些缺点的改进型(DDQN,Dueling DQN等),这些方法在dynamic programming的基础上建立起了复杂的RL算法系统,但是这些方法的根本想法是类似的,都是试图又简单到复杂(从随机初始化不断优化更新)最终获得关于全空间的价值信息。在获得了这些信息之后,agent每走到一个状态state,就会根据已知的环境信息看一下接下来的动作(到达的状态)的价值几何,之后简单地选择一个价值最高的action去执行。这样的方法看起来已经足够简单,但是实际上还是绕了个弯。在dynamic programming方法中我们主要的着眼点是环境,一直在力图通过建立value function的方法对环境信息有清楚明白的认知,至于策略嘛,在执行的过程中再看一下环境就知道了。但是Reinforcement Learning的最终目标是什么?并不是完整的环境信息,而是一个优秀的policy。优化policy才是我们的最终目标。与Dynamic Programming方法不同,Policy Optimization方法直接着眼于优化policy,从而开辟了一个新天地。
二、Policy Optimization概述
首先我们讨论一下什么是policy。policy是RL中agent的核心,接收环境提供的状态s,输出一个action给到环境。具体来说,policy接受state的输入,输出一个action的分布。我们使用神经网络对policy进行建模,policy的参数就是网络的权重。我们的目标是获得一个最优秀的policy,在这种定义情况之下指的就是期望获得policy参数
为什么要使用policy optimization方法?主要有如下的三个原因
-
有的时候策略
比value function(Q、V)更加简单 例如robotic grasp任务
-
V价值函数不能直接规定action,需要在模型已知的情况下使用argmax函数进行计算
-
Q价值函数虽然相比V价值函数求解动作更为方便,但是也需要遍历所有的动作,这对连续空间/高位动作空间情况提供了挑战
使用一张表格对Policy Optimization方法以及Dynamic Programming方法的优劣进行总结
| Policy Optimization | Dynamic Programming | |
|---|---|---|
| Conceptually | 优化我们真正关心的最终目标—policy | 不直接,依据自洽性,利用问题的结构(MDP) |
| Empirically | 只能是on-policy方法。适应性更强,用途更广 | off-policy方法,探索性更强;对于采样的效率更高 |
三、Likelihood Ratio Policy Gradient
根据刚才对policy的定义,我们对policy的优化实际上是为了求得
正如上边(1)式所表示的,
接下来对(1)式进行梯度计算的数学推导
通过以上推导,我们就获得了利用采样方法对policy评估函数
由(3)式结合梯度下降的原理,我们可以进行定性分析。如果按照
-
为正的trajectory出现的概率会增加( 增加) -
为负的trajectory出现的概率会降低( 降低)
通过梯度下降更新,我们按照以上原则改变了原先policy中不同价值的路径出现的概率,从而达到对路径进行优化的目的,但是实际上并没有对路径进行改变。
如何计算(3)式呢?我们需要对其中
由上边的推导可以得到,只需要知道trajectory上每一步的策略就可以对policy参数
考虑根据以上计算出的梯度结果进行梯度下降优化计算。根据之前的论述,我们达到的效果是当tragectory
从数学上可以证明,引入与action选择(trajectory)无关的b项对梯度值的求解没有影响
在(5)式中我们用采样的方法计算出了policy价值评估函数的梯度值,之前通过将
正如以上计算过程,我们在使用
(8)式就是经典的Policy
Gradient算法核心表达式,根据m次trajectory采样的结果计算了当前policy的梯度,用以对policy进行优化,之后重复这一过程,就可以得到满足要求的policy。值得注意的是,在这种表达式下baseline项b的含义也有所改变,之前其代表整个trajectory获得rewards的“平均值”或者是“标准”,但是在舍弃t时刻之前获得的奖励之后,b就变成了从当前时刻出发之后能够获得的奖励估计值。我们在这里将其写作
在具体操作的时候会面临一个问题。如何选择baseline?这个问题相当关键,事实上PG算法很多的优化版本正式针对baseline选择这个问题进行的改进。我们引入baseline(6)式中的b项代表一个constant
baseline,表示整个trajectory的rewards平均值,即
这种设置方法虽然简便,但是更多的将baseline认为是一个时间t的函数。这样的做法固然可取,但是在不同的trajectory中时间t时所处在的state不同,众所周知出发的state对之后能取得奖励的大小有着决定性的影响,这种影响比探索时间更加重要一些,并且由于时间限制H通常很大,将baseline设定成
如何计算
这是一种完全类似于supervised learning的想法,具有很好的效果。介绍另一种方法,是我们之前比较熟悉的TD(时序差分)方法。TD方法利用Bellman Equation进行迭代,与Monte-Carlo方法直接采样获得m个完整的trajectory不同,TD方法则是走一步优化一次,优化更新的频率高于Monte-Carlo方法。Bellman Equation是:
我们根据这个式子进行迭代优化。
 进行了这么多理论分析,左图是Vanilla Policy Gradient(最标准的普通PG算法)的流程。可以看到VPG算法遵循Monte-Carlo方法计算state-dependent
baseline函数,之后再对
进行了这么多理论分析,左图是Vanilla Policy Gradient(最标准的普通PG算法)的流程。可以看到VPG算法遵循Monte-Carlo方法计算state-dependent
baseline函数,之后再对
回顾一下Likelihood Ratio PG Estimator,即
这里着重标出了A项。A项
再通过引入函数
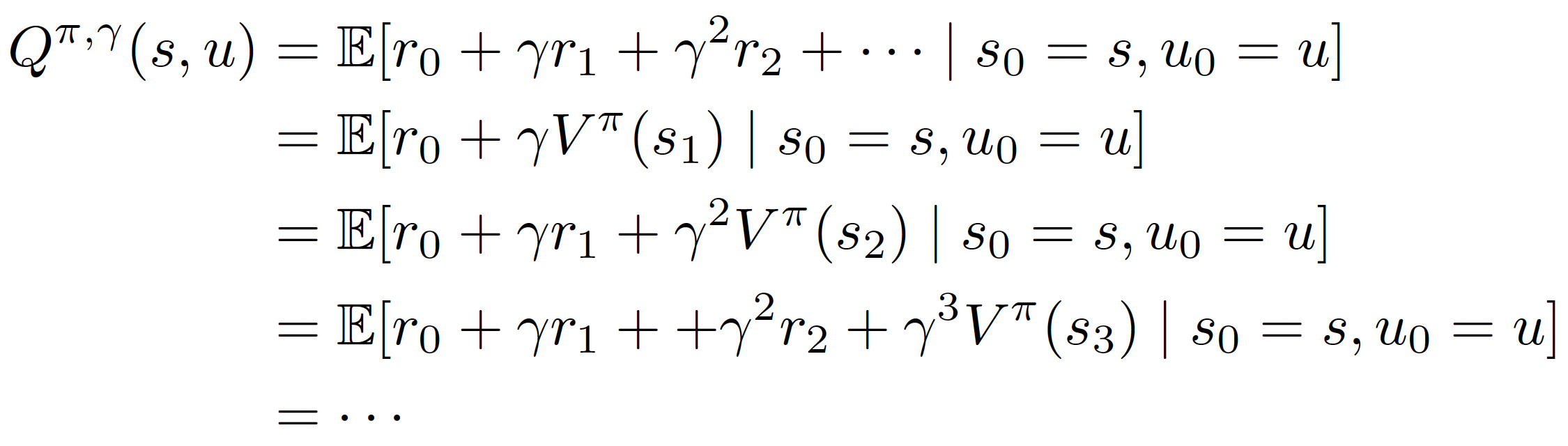
使用上边的折扣因子Q函数代替(9)式中的A项,就是著名的A3C(Asynchronous Advantage Actor-Critic)算法的核心思路。另外还有一个著名的算法也使用了类似的这种思路
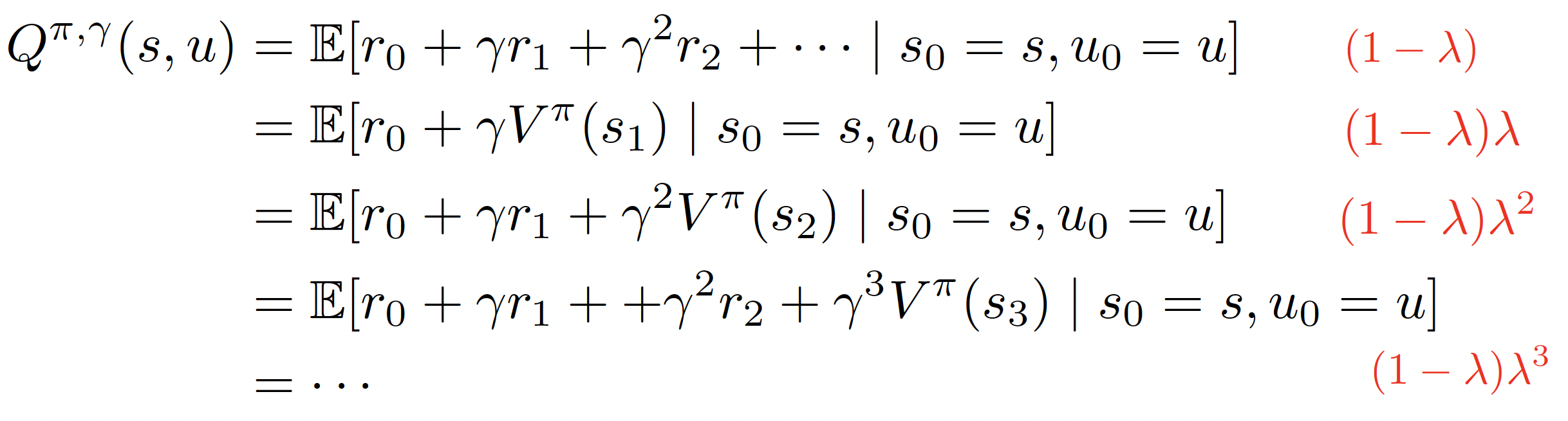
对以上的不同step采样估计的Q函数进行加权平均,权重如右侧红色字体所示,最终获得一个gereralized的Q函数带入进行PG计算,这种方法就是著名的GAE(Generalized Advantage Estimation)算法。A3C算法亦或是GAE算法,他们本质上都是Actor-Critic算法。有关Actor-Critic的内容之后也会涉及,这是RL中相当重要且前沿的一个部分。简单的说,Actor-Critic指的就是利用value function baseline的PG算法。在这里将GAE算法的大致流程列在下边,之后还会进行更详细的讨论。
